Select Research Projects
AI and Vision in Agriculture
Agtech Framework for Cranberry-Ripening Analysis Using Vision Foundation Models
Johnson, Faith, Ryan Meegan, Jack Lowry, Peter Oudemans, and Kristin Dana. 2025. “Agtech Framework for Cranberry-Ripening Analysis Using Vision Foundation Models.” Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 1207–1216.
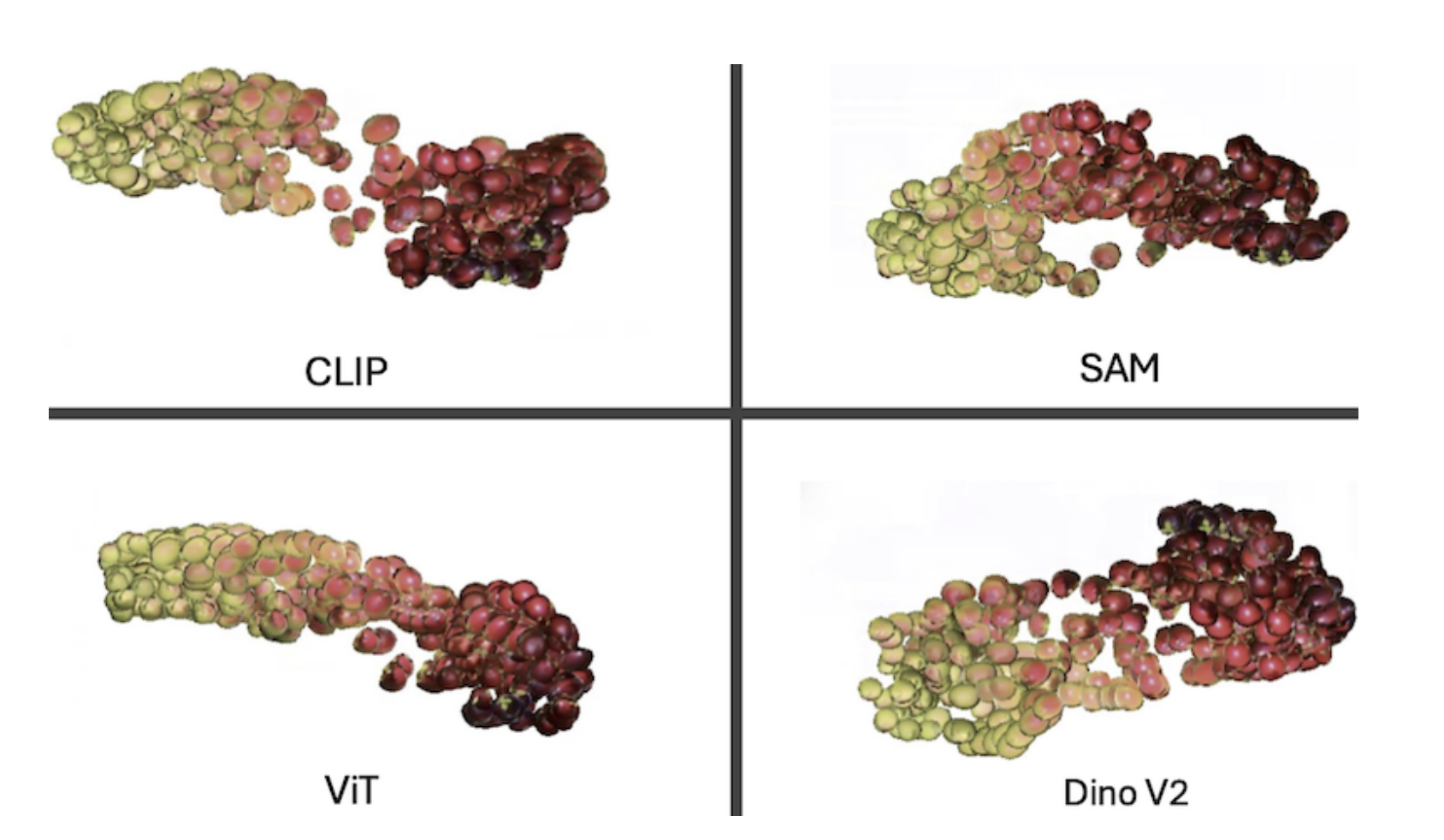
This work presents a computer vision framework for analyzing the ripening process of cranberry crops using both aerial drone and ground-based imaging across a full growing season. By leveraging vision transformers (ViT) and UMAP dimensionality reduction, the framework enables interpretable visualizations of berry appearance and quantifies ripening trajectories. The approach supports precision agriculture tasks such as high-throughput phenotyping and crop variety comparison. This is the first visual framework for cranberry ripening assessment, with potential impact across other crops like wine grapes and olives.
[BibTeX] | [Project Page]Vision on the bog: Cranberry crop risk evaluation with deep learning
Akiva, Peri, Benjamin Planche, Aditi Roy, Peter Oudemans, and Kristin Dana. "Vision on the bog: Cranberry crop risk evaluation with deep learning." Computers and Electronics in Agriculture 203 (2022)

Vision-on-the-bog is framework for smart agriculture that enables real-time decision-making by monitoring cranberry crops. It performs instance segmentation to count sun-exposed cranberries at risk of overheating and predicts internal berry temperature using drone and sky imaging. A weakly supervised segmentation method reduces annotation effort, while a differentiable model jointly estimates solar irradiance and berry temperature. These tools support short-term risk assessment to inform irrigation decisions. The approach is validated over two growing seasons and can be extended to crops such as grapes, olives, and grain.
[BibTeX] | [Project Page]Visual Navigation
A Landmark-Aware Visual Navigation Dataset
Akiva, Peri, Benjamin Planche, Aditi Roy, Peter Oudemans, and Kristin Dana. "Vision on the bog: Cranberry crop risk evaluation with deep learning." Computers and Electronics in Agriculture 203 (2022)
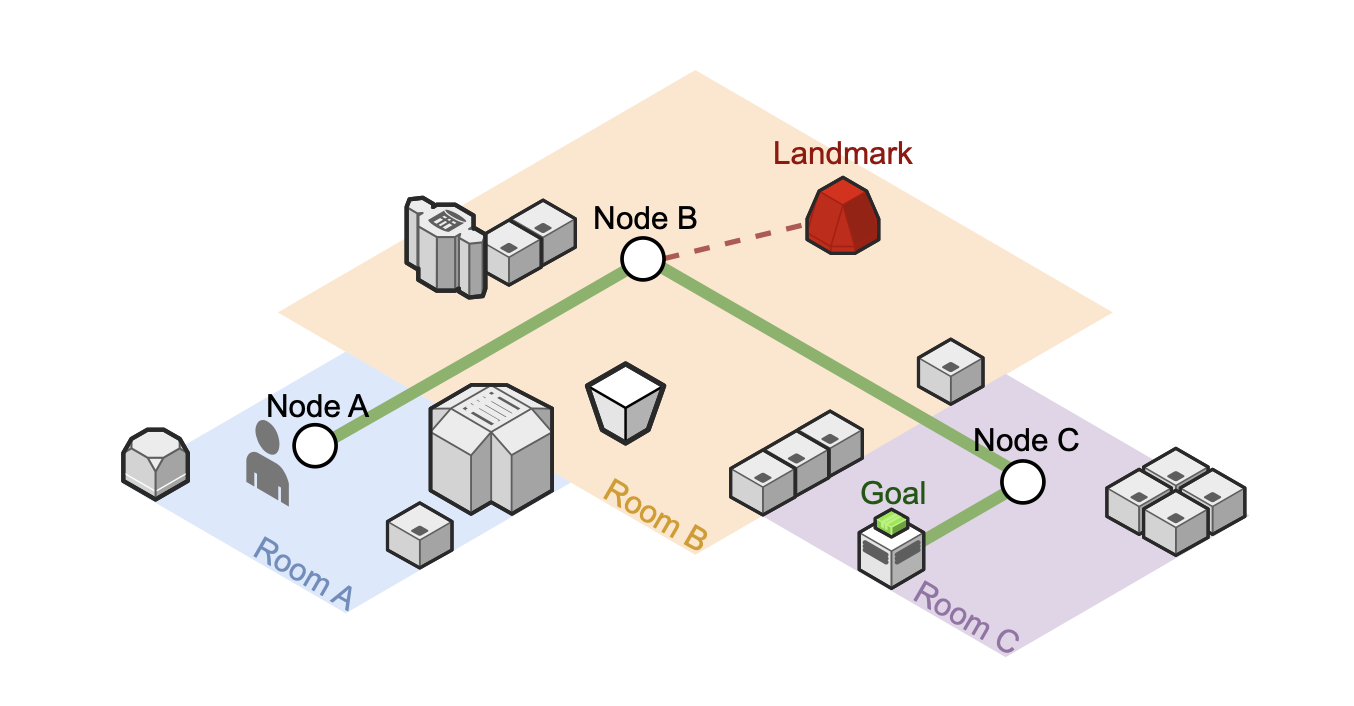
This work introduces the Landmark-Aware Visual Navigation (LAVN) dataset to support supervised learning of human-centric exploration and map-building policies. The dataset includes RGB-D observations, human point-clicks for navigation waypoints, and annotated visual landmarks from both virtual and real-world environments. These annotations enable direct supervision for learning efficient exploration strategies and landmark-based mapping. LAVN spans diverse scenes and is publicly released with comprehensive documentation to facilitate research in visual navigation.
[BibTeX] | [Project Page]Feudal Networks for Visual Navigation
Johnson, Faith, Bryan Bo Cao, Ashwin Ashok, Shubham Jain, and Kristin Dana. "Feudal networks for visual navigation.", presented at Embodied AI Workshop EAI-CVPR2024, arXiv preprint arXiv:2402.12498 (2024)
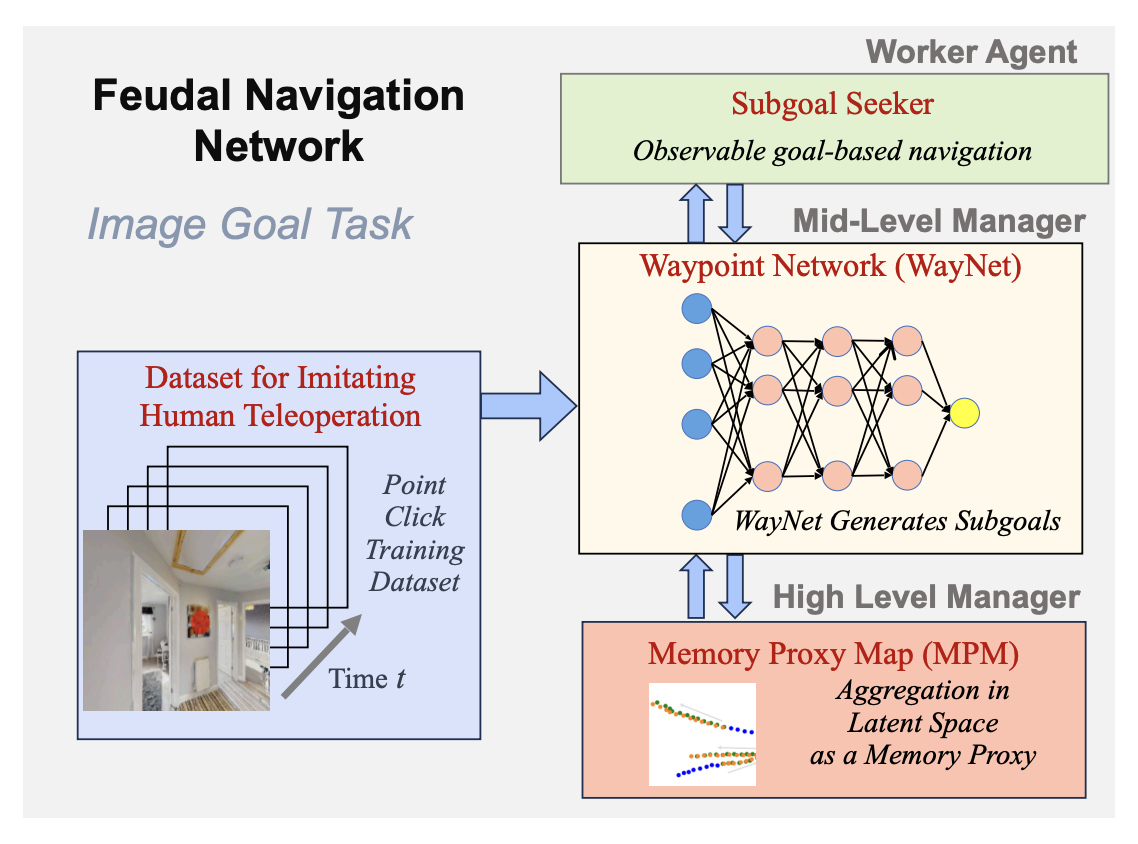
This work proposes a novel feudal learning approach to visual navigation that eliminates the need for reinforcement learning, metric maps, graphs, or odometry. The hierarchical architecture includes a high-level manager with a self-supervised memory proxy map and a mid-level manager with a waypoint network trained to mimic human navigation behaviors. Each level of the agent hierarchy operates at different spatial and temporal scales, enabling efficient, human-like exploration. The system is trained using a small set of teleoperation videos and achieves near state-of-the-art performance on image-goal navigation tasks in previously unseen environments.
[BibTeX] | [Project Page]Learning a Pedestrian Social Behavior Dictionary
Johnson, Faith, and K. Dana. "Learning a Pedestrian Social Behavior Dictionary." British Machine Vision Conference, 2023.

This work presents an unsupervised framework for learning a dictionary of pedestrian behaviors from trajectory data, enabling semantic interpretation without the need for labeled examples. A trajectory latent space is learned and clustered to form a taxonomy of behaviors specific to the environment. This dictionary is then used to generate behavior maps that visualize how pedestrians use space and to compute distributions over different behavior types. By conditioning on behavior labels, the method enables a simple yet effective approach to trajectory prediction. The lightweight, low-parameter model achieves results comparable to state-of-the-art methods on the ETH and UCY benchmark datasets.
[BibTeX] | [Project Page]| [Paper]Photographic Steganography and Watermarking
Light Field Messaging With Deep Photographic Steganography
Wengrowski, Eric, and Kristin Dana. "Light field messaging with deep photographic steganography." In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 1515-1524. 2019.

We develop Light Field Messaging (LFM), a process of embedding, transmitting, and receiving hidden information in video that is displayed on a screen and captured by a handheld camera. The goal of the system is to minimize perceived visual artifacts of the message embedding, while simultaneously maximizing the accuracy of message recovery on the camera side. LFM requires photographic steganography for embedding messages that can be displayed and camera-captured. Unlike digital steganography, the embedding requirements are significantly more challenging due to the combined effect of the screen's radiometric emittance function, the camera's sensitivity function, and the camera-display relative geometry. We devise and train a network to jointly learn a deep embedding and recovery algorithm that requires no multi-frame synchronization. A key novel component is the camera display transfer function (CDTF) to model the camera-display pipeline. To learn this CDTF we introduce a dataset (Camera-Display 1M) of 1,000,000 camera-captured images collected from 25 camera-display pairs. The result of this work is a high-performance real-time LFM system using consumer-grade displays and smartphone cameras.
[BibTeX] | [Project Page]Vision+Tactile
Teaching Cameras to Feel: Estimating Tactile Physical Properties of Surfaces from Images
Purri, Matthew, and Kristin Dana. "Teaching Cameras to Feel: Estimating Tactile Physical Properties of Surfaces from Images." *European Conference on Computer Vision (ECCV)*, 2020.
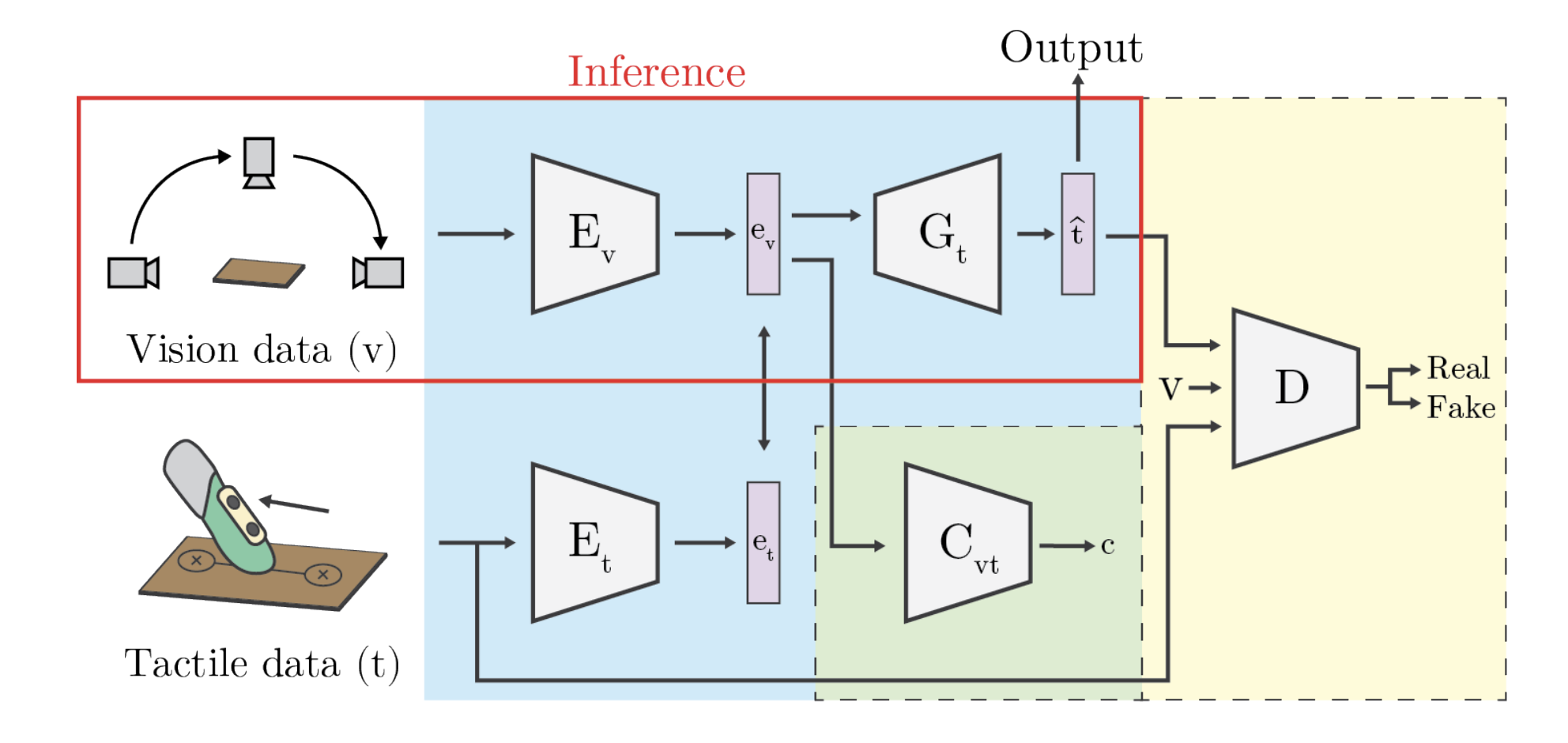
This work introduces a novel task of estimating 15 tactile physical properties—such as friction, compliance, adhesion, and thermal conductance—from visual images using a multi-view dataset of over 400 surfaces. The authors propose a cross-modal framework combining adversarial objectives and a joint visuo-tactile classification loss, along with neural architecture search to optimally select viewpoints. Results demonstrate effective prediction of material properties purely from images. The dataset formed (Surface Property Synesthesia Dataset) is among the largest to tackle vision-to-touch prediction and is publicly released.
[BibTeX] | [Project Page]Segmentation and Object Detection
Self‑Supervised Object Detection from Egocentric Videos
Akiva, Peri, Jing Huang, Kevin J. Liang, Rama Kovvuri, Xingyu Chen, Matt Feiszli, Kristin Dana, and Tal Hassner. 2023. “Self‑Supervised Object Detection from Egocentric Videos.” *Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)*, 5225–5237.
This paper presents DEVI, a self-supervised, class-agnostic object detector trained on egocentric video without annotations or pretraining. It uses multi-view and scale-regression losses—motivated by appearance-based cues—to learn dense, category-specific features. The learned cluster residual module enables robust object localization in complex environments. DEVI achieves significant gains in detection metrics on the Ego4D and EgoObjects datasets while using a lightweight, end-to-end architecture.
[BibTeX] | [Project Page]Single Stage Weakly Supervised Semantic Segmentation of Complex Scenes
Akiva, P. & Dana, K. (2023). Single Stage Weakly Supervised Semantic Segmentation of Complex Scenes*. In 2023 IEEE Winter Conference on Applications of Computer Vision (WACV), 5943–5954.
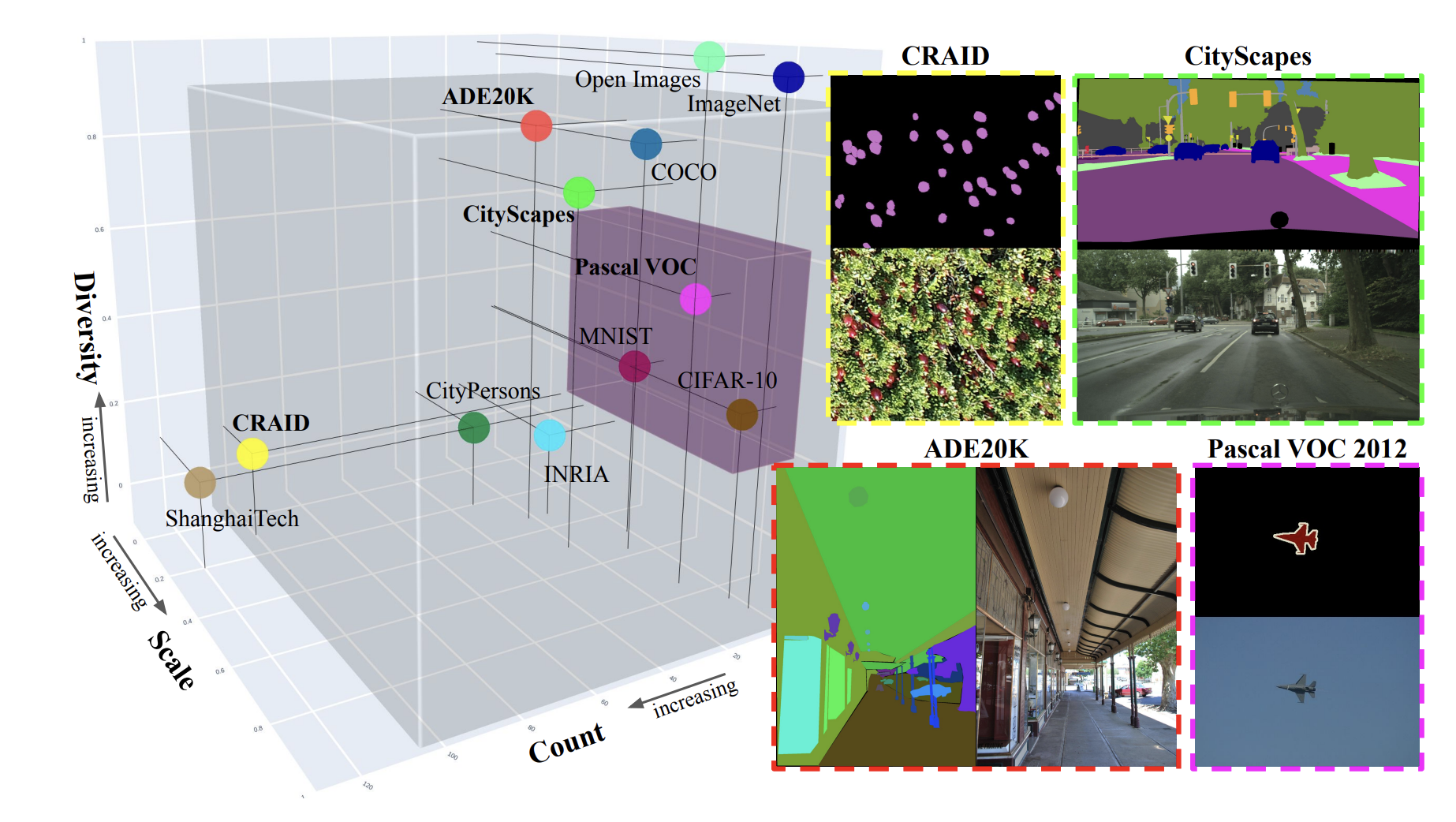
This paper presents a single-stage method for weakly‑supervised semantic segmentation using point annotations to generate reliable pseudo‑masks on the fly, eliminating the need for pre‑training, multi‑stage pipelines, or refined CAMs. It achieves state‑of‑the‑art performance across challenging real‑world benchmarks such as CRAID, CityPersons, ADE20K and CityScapes, showing advantages in both accuracy and generalizability. The method is trained from scratch, handles complex scenes, and outperforms multi‑stage methods that rely on pre‑trained networks. Its innovation lies in combining expanding distance fields with pixel‑adaptive convolutions to refine masks at each training step.
[BibTeX] [Project Page]Remote Sensing
Urban Semantic 3D Reconstruction from Multiview Satellite Imagery
Leotta, M. J., Long, C., Jacquet, B., Zins, M., Lipsa, D., Shan, J., Xu, B., Li, Z., Zhang, X., Chang, S.‑F., Purri, M., Xue, J., & Dana, K. (2019). Urban Semantic 3D Reconstruction from Multiview Satellite Imagery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops.
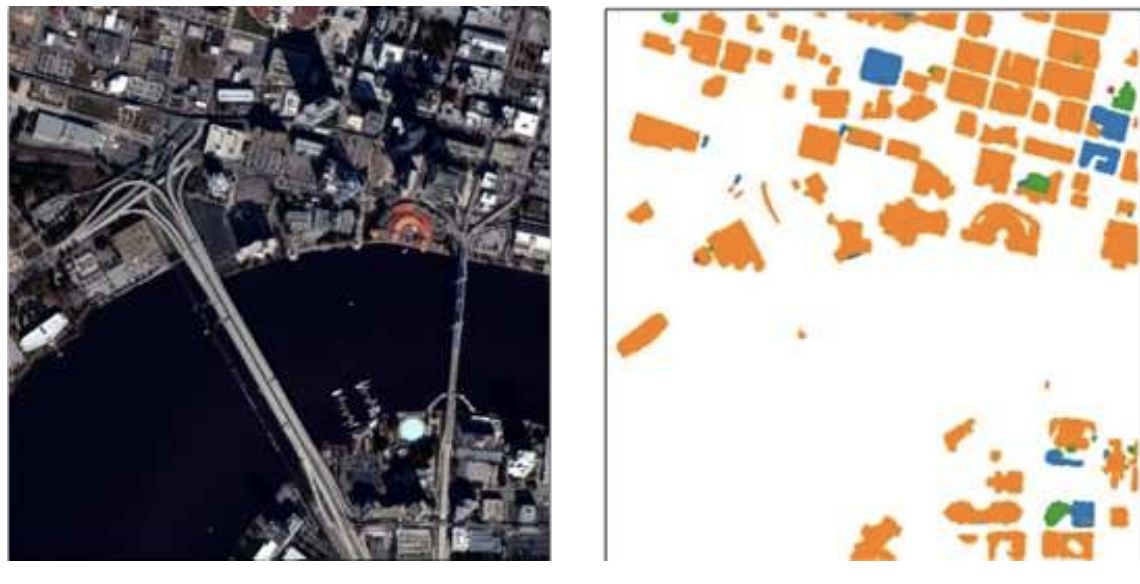
We present a system that segments buildings and bridges from terrain using multiview satellite imagery, and reconstructs low‑polygon textured 3D meshes with preserved sharp edges. Our method focuses on semantic segmentation and regularized surface extraction, evaluated on the IARPA CORE3D dataset. A web‑based AWS application enables users to deploy algorithms and visualize results, with both code and interface released as open-source. This addresses challenges of dense, “melted” point‑cloud models and a lack of semantic separation.
[BibTeX] | [Project Page]H2O‑Net: Self‑Supervised Flood Segmentation via Adversarial Domain Adaptation and Label Refinement
Akiva, Peri, Matthew Purri, Kristin J. Dana, Beth Tellman, and Tyler Anderson. 2020. “H2O‑Net: Self‑Supervised Flood Segmentation via Adversarial Domain Adaptation and Label Refinement.” In *Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)*, 111–122.
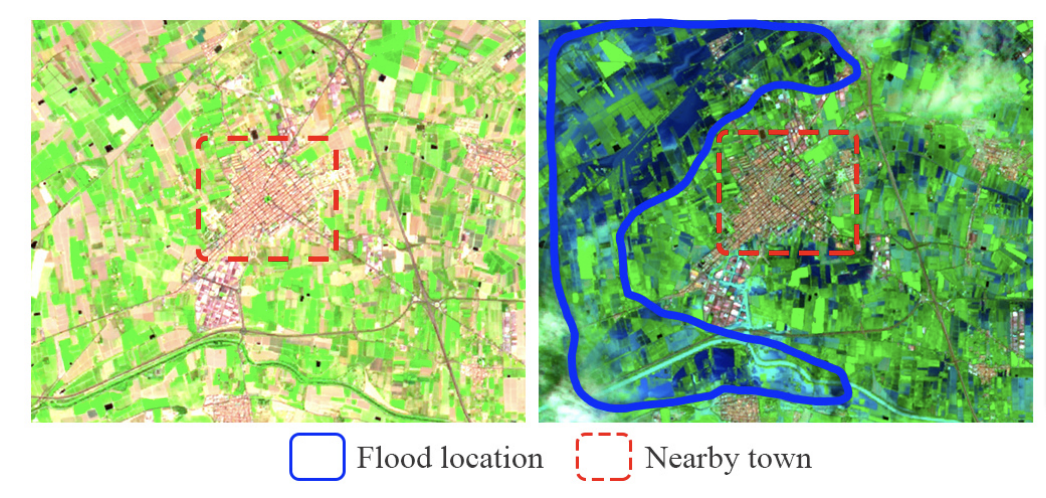
H2O‑Net presents a self‑supervised deep-learning method for flood segmentation by bridging domain gaps between low‑resolution government satellite imagery and high‑resolution commercial satellite/drone imagery using adversarial adaptation and label refinement. It synthesizes SWIR-like signals to enhance water detection, then refines coarse masks via a self‑supervised mechanism, requiring no manual annotations. The model achieves ~10–12% improvements in pixel accuracy and mIoU over state-of-the-art methods and generalizes well across sensors. The approach supports rapid flood mapping and demonstrates real-world viability for disaster response.
[BibTeX] | [Project Page]Material Segmentation of Multi-View Satellite Imagery
Purri, Matthew, Jia Xue, Kristin Dana, Matthew Leotta, Dan Lipsa, Zhixin Li, Bo Xu, and Jie Shan. "Material segmentation of multi-view satellite imagery." arXiv preprint arXiv:1904.08537 (2019).
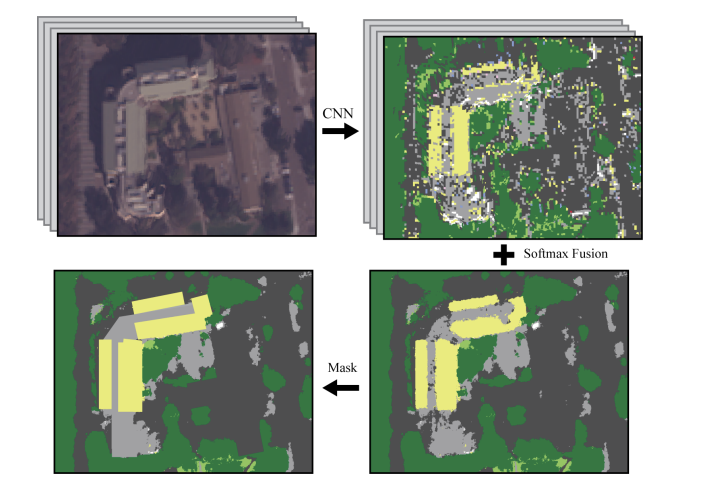
This work presents a novel pipeline for material segmentation using multi-view satellite imagery, addressing the challenge of combining low-resolution panchromatic and multispectral data. A specialized CNN architecture is introduced that learns both spatial and angular reflectance cues for improved material classification. The model is trained and evaluated using the SpaceNet 6 dataset and demonstrates significant gains over baseline methods in segmenting roads, buildings, and natural terrain. The study underscores the importance of angular diversity in satellite viewpoints for material understanding.
[BibTeX] | [Project Page]Texture/Material
Differential Viewpoints for Ground Terrain Material Recognition
Xue, Jia, Hang Zhang, Ko Nishino, and Kristin J. Dana. "Differential viewpoints for ground terrain material recognition." IEEE Transactions on Pattern Analysis and Machine Intelligence 44, no. 3 (2020): 1205-1218.

This work introduces a multi-view approach to terrain material classification by analyzing appearance variations from different viewpoints. A convolutional neural network is trained to learn discriminative features across angular changes, improving recognition accuracy on outdoor surfaces. Benchmark results on a novel dataset show significant performance gains over single-view baselines. The method highlights the importance of viewpoint diversity in robust material perception.
[BibTeX] | [Project Page]Photo-realistic Facial Texture Transfer
Kaur, Parneet, Hang Zhang, and Kristin Dana. "Photo-realistic facial texture transfer." In 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), pp. 2097-2105. IEEE, 2019.
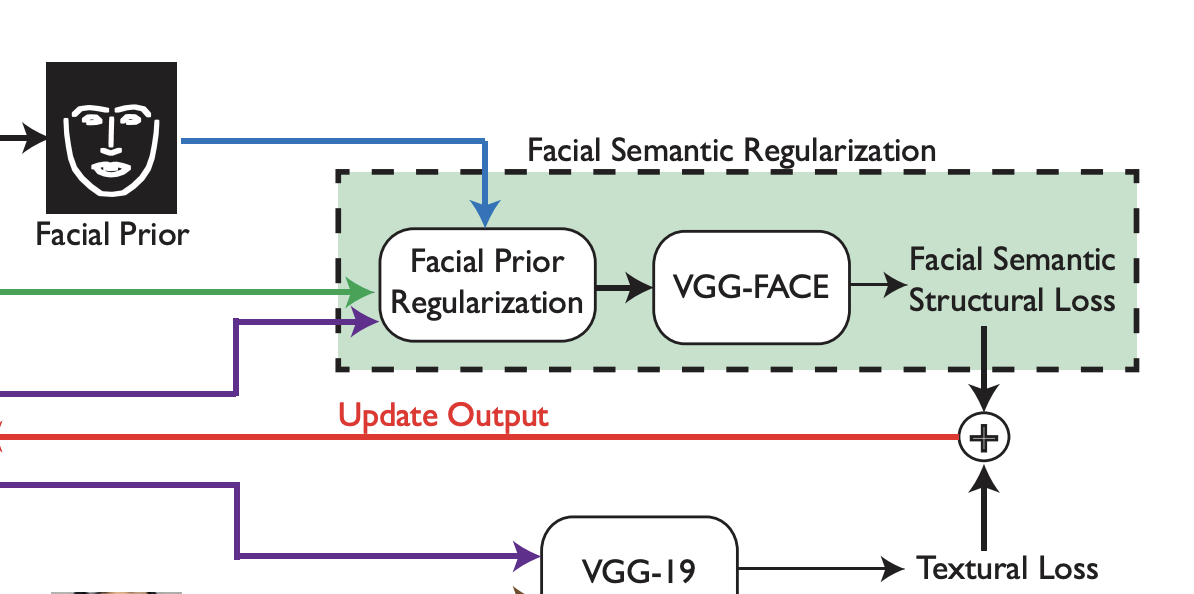
This paper presents a method for photo-realistic facial texture transfer that maintains high-frequency identity details while adapting global appearance. The approach uses a hybrid deep learning model to align features between a source and target domain. Applications include facial editing, animation, and virtual reality content synthesis.
Deep TEN: Texture Encoding Network
Zhang, Hang, Xue, Jia, and Dana, Kristin. 2017. “Deep TEN: Texture Encoding Network.” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 708–717.
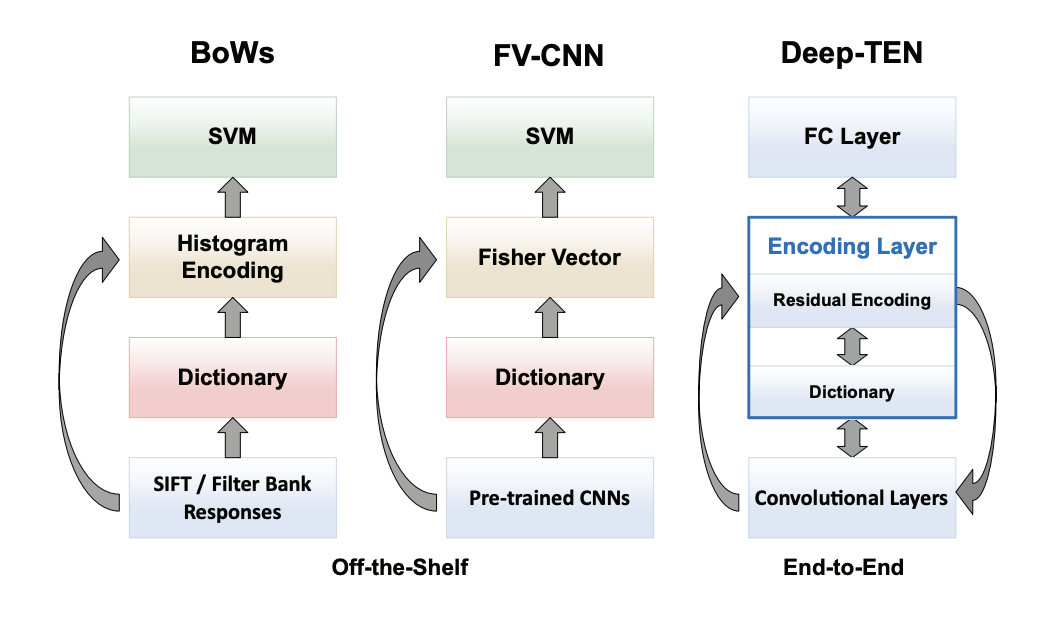
Deep TEN introduces an end-to-end trainable texture encoding layer within CNNs to enhance texture recognition. The model aggregates deep local features into a robust global descriptor, significantly improving texture classification performance. It sets new benchmarks on multiple texture and material datasets.
Reflectance Hashing for Material Recognition
Zhang, Hang, Kristin Dana, and Ko Nishino. "Reflectance hashing for material recognition." In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3071-3080. 2015.
We introduce a novel method for using reflectance to identify materials. Reflectance offers a unique signature of the material but is challenging to measure and use for recognizing materials due to its high-dimensionality. In this work, one-shot reflectance of a material surface which we refer to as a reflectance disk is capturing using a unique optical camera. The pixel coordinates of these reflectance disks correspond to the surface viewing angles. The reflectance has class-specific stucture and angular gradients computed in this reflectance space reveal the material class. These reflectance disks encode discriminative information for efficient and accurate material recognition. We introduce a framework called reflectance hashing that models the reflectance disks with dictionary learning and binary hashing. We demonstrate the effectiveness of reflectance hashing for material recognition with a number of real-world materials.
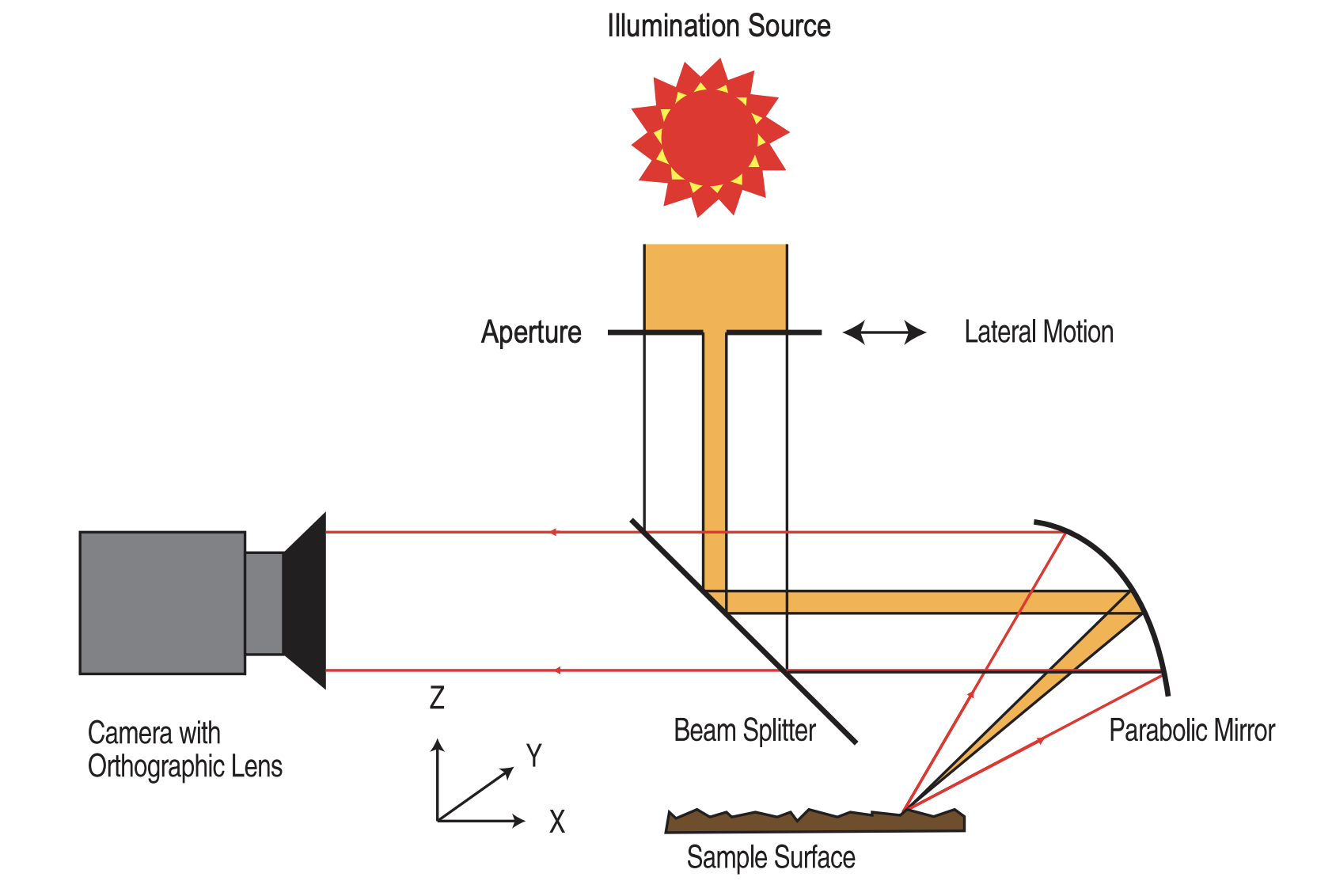
Relief Texture from Specularities
Wang, Jing, and Kristin J. Dana. "Relief texture from specularities." IEEE Transactions on pattern analysis and machine intelligence 28, no. 3 (2006): 446-457.


This work introduces a novel method to capture fine-scale surface geometry, or relief texture, which is critical for realistic rendering and accurate object modeling. Traditional scanners often miss such detail—especially on specular or partially specular surfaces—due to light scattering. We develop a custom imaging device using a concave parabolic mirror that captures multiple viewing angles in a single image, enabling high-resolution recovery of both surface shape and spatially varying reflectance. Unlike laser scanning, this approach is tailored to specular materials and captures both texture shape and color simultaneously.
Reflectance and Texture of Real-World Surfaces
Dana, Kristin J., Bram Van Ginneken, Shree K. Nayar, and Jan J. Koenderink. "Reflectance and texture of real-world surfaces." ACM Transactions On Graphics (TOG) 18, no. 1 (1999): 1-34.


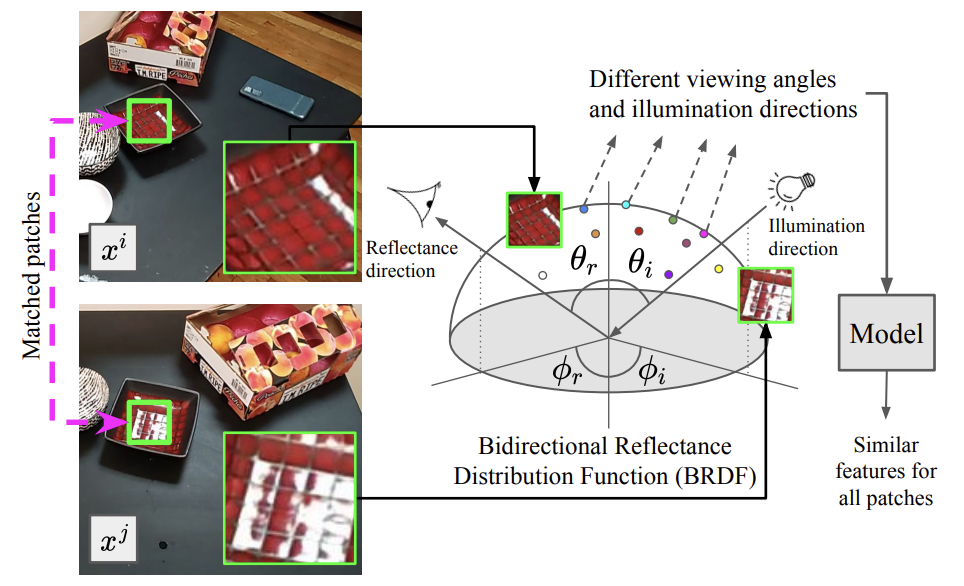
In this work, we investigate the visual appearance of real-world surfaces and the dependence of appearance on the geometry of imaging conditions. We discuss a new texture representation called the BTF (bidirectional texture function) which captures the variation in texture with illumination and viewing direction. We present a BTF and BRDF database with image textures from over 60 different samples, each observed with over 200 different combinations of viewing and illumination directions. Both of these unique databases are publicly available and have important implications for computer graphics.
Inspection Robots
Automated Crack Detection on Concrete Bridges
Prasanna, Prateek, Kristin J. Dana, Nenad Gucunski, Basily B. Basily, Hung M. La, Ronny Salim Lim, and Hooman Parvardeh. "Automated crack detection on concrete bridges." IEEE Transactions on automation science and engineering 13, no. 2 (2014): 591-599.

Detection of cracks on bridge decks is a vital task for maintaining the structural health and reliability of concrete bridges. Robotic imaging can be used to obtain bridge surface image sets for automated on-site analysis. We present a novel automated crack detection algorithm, the STRUM (spatially tuned robust multifeature) classifier, and demonstrate results on real bridge data using a state-of-the-art robotic bridge scanning system. A crack density map for the bridge mosaic provides a computational description as well as a global view of the spatial patterns of bridge deck cracking. The bridges surveyed for data collection and testing include Long-Term Bridge Performance program's (LTBP) pilot project bridges at Haymarket, VA, USA, and Sacramento, CA, USA.
Automated GPR Rebar Analysis for Robotic Bridge Deck Evaluation
Kaur, Parneet, Kristin J. Dana, Francisco A. Romero, and Nenad Gucunski. "Automated GPR rebar analysis for robotic bridge deck evaluation." IEEE transactions on cybernetics 46, no. 10 (2015): 2265-2276.
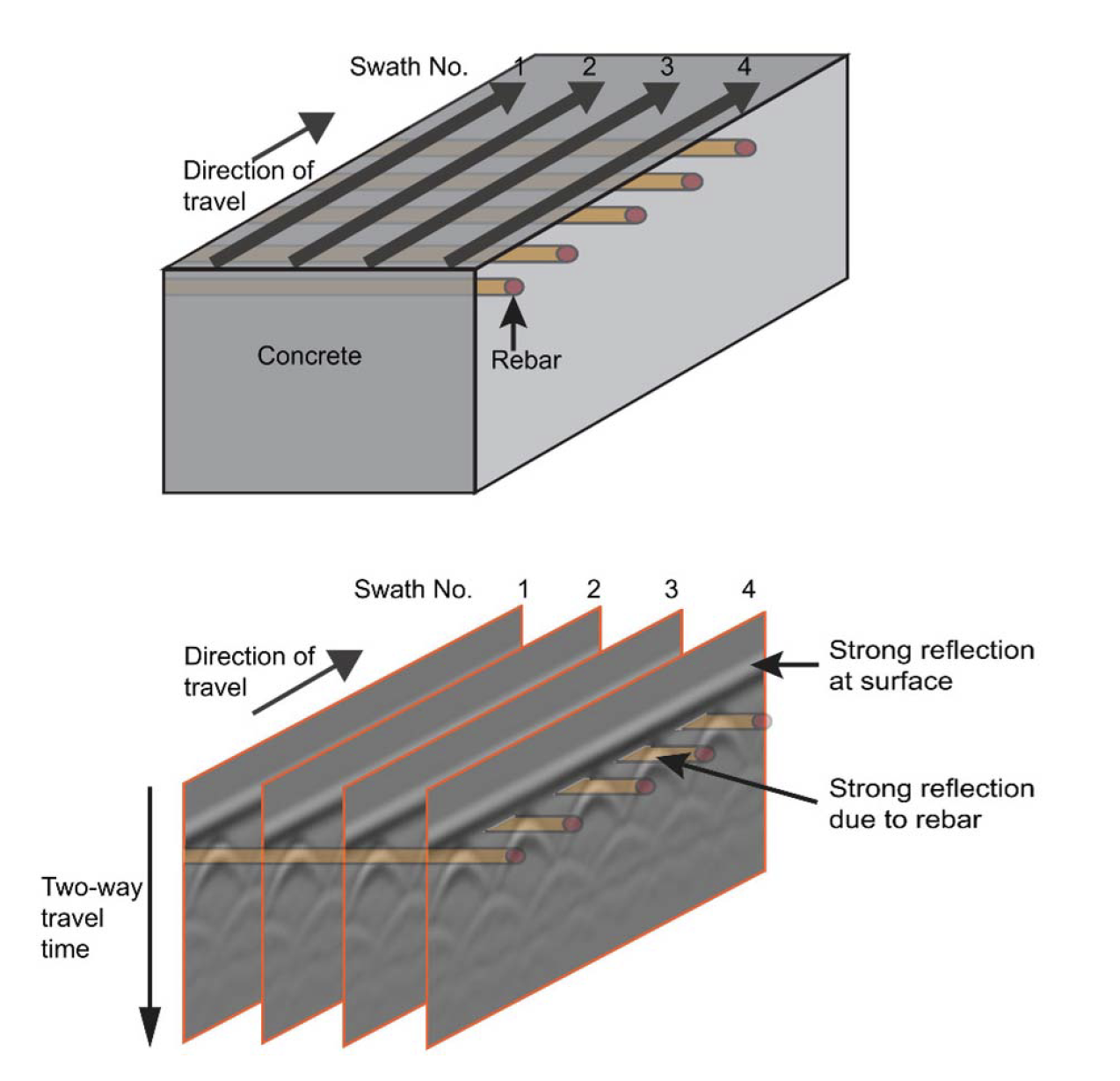
Ground penetrating radar (GPR) is used to evaluate deterioration of reinforced concrete bridge decks based on measuring signal attenuation from embedded rebar. The existing methods for obtaining deterioration maps from GPR data often require manual interaction and offsite processing. In this paper, a novel algorithm is presented for automated rebar detection and analysis. We test the process with comprehensive measurements obtained using a novel state-of-the-art robotic bridge inspection system equipped with GPR sensors. The algorithm achieves robust performance by integrating machine learning classification using image-based gradient features and robust curve fitting of the rebar hyperbolic signature. High rates of accuracy are reported on real data that includes thousands of individual hyperbolic rebar signatures from three real bridge decks.
Quantitative Dermatology
From Photography to Microbiology: Eigenbiome Models for Skin Appearance
Kaur, Parneet, Kristin J. Dana, and Gabriela Oana Cula. "From photography to microbiology: Eigenbiome models for skin appearance." In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (BioImage Computing), pp. 1-10. 2015
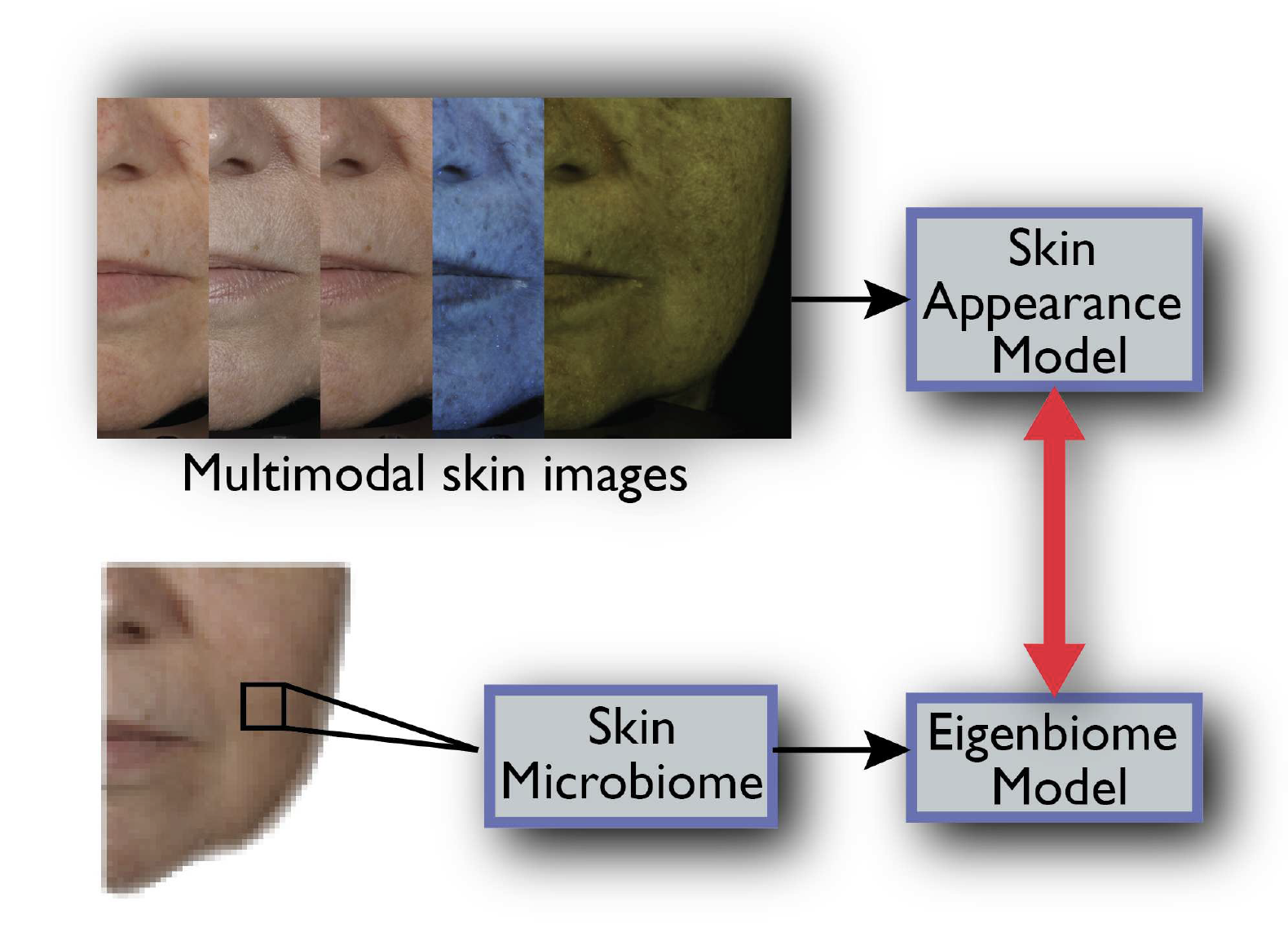
This work introduces Eigenbiome, a statistical model that links photographic skin appearance to underlying microbial community features using unsupervised dimensionality reduction. By capturing texture and color patterns in a low-dimensional “appearance space,” the framework infers likely microbiome compositions without direct sampling. Experiments on real facial and forearm imagery show strong correlations between appearance-based vectors and measured bacterial profiles. The approach opens a new avenue for non-invasive skin health monitoring and microbiome estimation.
Multimodal and Time‑Lapse Skin Registration
Madan, Siddharth, Cula, Gabriella Oana, & Dana, Kristin. 2015. “Multimodal and Time‑Lapse Skin Registration.” *Skin Research Technology*, 21(3): 319–326.
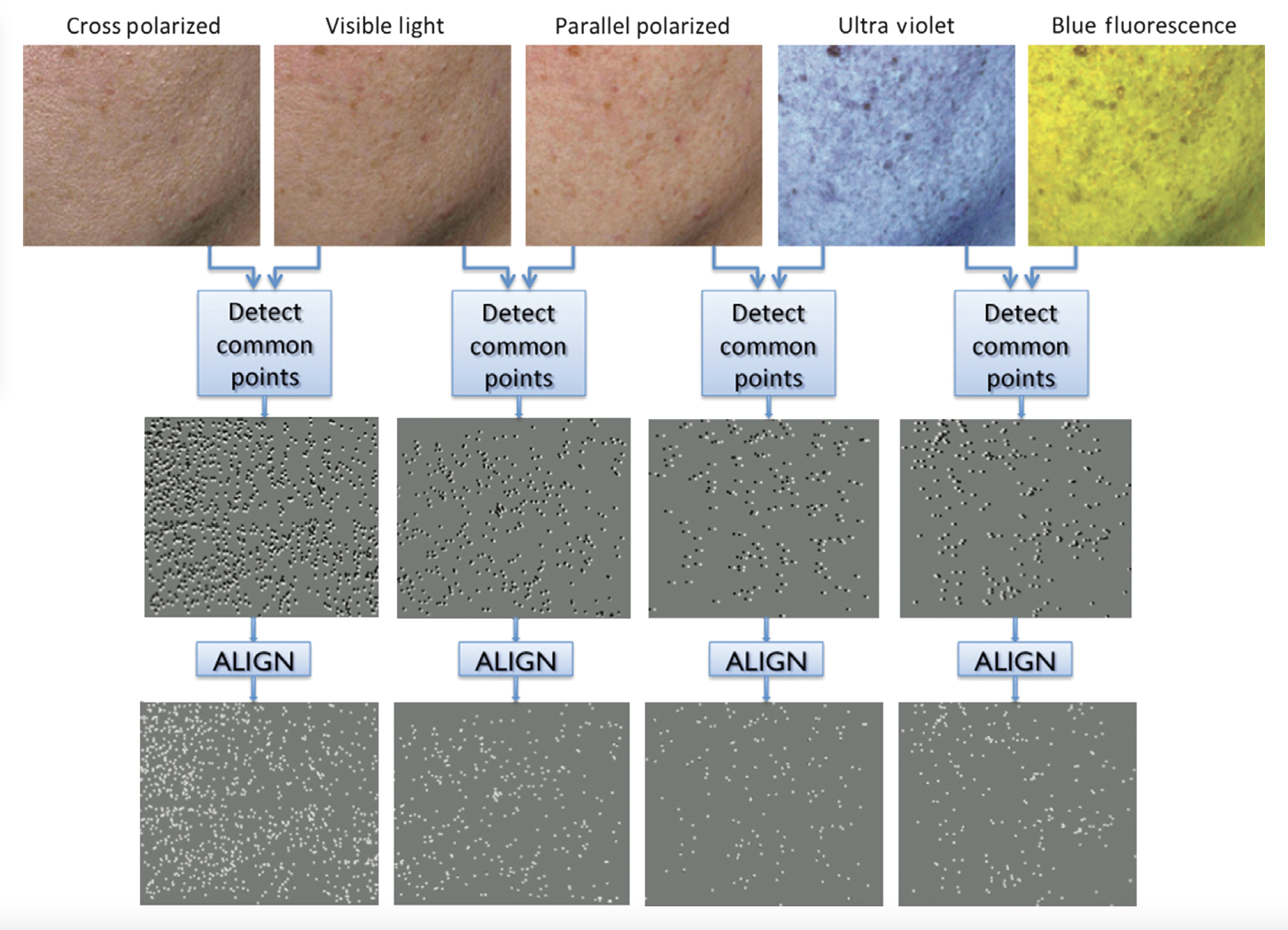
This paper presents a registration framework for aligning multimodal (reflectance and fluorescence) and time‑lapse skin images at subpixel resolution despite motion variations. The system automatically detects micro‑features like pores and tracks them over weeks to monitor lesion evolution. Results show high alignment accuracy, improving downstream quantitative skin analysis. This robust alignment method enhances data quality for dermatological research and clinical monitoring.
Skin Texture Modeling
Cula, Oana G., Kristin J. Dana, Frank P. Murphy, and Babar K. Rao. "Skin texture modeling." International Journal of Computer Vision 62 (2005): 97-119.

This work introduces a deep model for learning skin micro- and macro-texture features, combining local descriptors and global mapping for clinical classification of dermatological conditions. The system incorporates a texture-encoding branch to capture fine geometric skin patterns, validated on clinical and consumer images. It achieves high accuracy in classifying conditions like eczema and acne, outperforming baseline texture descriptors. This model supports interpretability by highlighting clinically relevant texture regions.